O Horizonte da Inteligência Artificial
Em dezembro de 2025, o ecossistema de Grandes Modelos de Linguagem (LLMs) atravessa um ponto de inflexão histórico. O paradigma anterior, dominado quase exclusivamente pela “Lei de Escala” (Scaling Laws) — que postulava que o aumento linear de parâmetros e dados resultaria em ganhos exponenciais de performance —, cedeu lugar a uma nova era de eficiência algorítmica, especialização arquitetural e raciocínio híbrido (“System 2”). A hegemonia do Transformer denso monolítico foi efetivamente desmantelada. Em seu lugar, emergiu uma classe heterogênea de arquiteturas esparsas (Mixture-of-Experts – MoE), mecanismos de atenção adaptativos e sistemas de computação dinâmica durante a inferência.
Este relatório técnico oferece uma dissecção profunda dos oito principais modelos que definem a fronteira tecnológica no final de 2025: GPT-5 (OpenAI), Claude 4 (Anthropic), Gemini 3 (Google), Llama 4 (Meta), DeepSeek-V3/R1 (DeepSeek), Qwen 3 (Alibaba), Grok 4 (xAI) e Mistral Large 3 (Mistral AI). A análise transcende as métricas superficiais de benchmark para investigar os componentes matemáticos subjacentes — especificamente as inovações em mecanismos de atenção (como Multi-Head Latent Attention, Ring Attention e FlexAttention) e estratégias de roteamento esparso — que permitiram a esses modelos superar as barreiras de memória e latência que limitavam seus predecessores.1
A análise revela que a “fronteira” não é mais uma linha única de avanço, mas uma ramificação em três direções distintas: modelos de raciocínio profundo (como DeepSeek-R1 e GPT-5 Thinking), que utilizam Reinforcement Learning from Verifiable Rewards (RLVR) para auto-verificação; modelos de contexto infinito (como Gemini 3 e Llama 4), capazes de processar até 10 milhões de tokens via distribuição de hardware; e modelos de agência autônoma (como Claude 4), otimizados para uso de ferramentas e persistência de memória.4
1. O Paradigma Arquitetural de 2025: A Morte do Transformer Baunilha
A transição de 2024 para 2025 marcou o fim da predominância do Transformer “Vanilla” (a arquitetura original proposta por Vaswani et al., 2017). Embora o mecanismo fundamental de auto-atenção (self-attention) permaneça como a espinha dorsal, a implementação prática nos modelos de fronteira diverge radicalmente da teoria clássica.
1.1 A Onipresença da Mistura de Especialistas (MoE)
A arquitetura densa, onde todos os parâmetros são ativados para cada token processado, tornou-se computacionalmente inviável para modelos na escala de trilhões de parâmetros. A solução universal adotada em 2025 é o MoE Esparso (Sparse Mixture-of-Experts). Esta abordagem desacopla o “tamanho do modelo” (capacidade de armazenamento de conhecimento) do “custo de inferência” (capacidade computacional ativa). Modelos como o DeepSeek-V3 e o Mistral Large 3 demonstram que é possível ter um modelo com 671 bilhões de parâmetros totais, mas ativar apenas 37 bilhões por token, mantendo a latência baixa sem sacrificar a densidade de conhecimento.3
1.2 A Revolução da Atenção: Superando o Custo Quadrático
O gargalo histórico dos Transformers era a complexidade quadrática O(N^2) da atenção em relação ao comprimento da sequência. Em 2025, inovações matemáticas permitiram janelas de contexto de até 10 milhões de tokens.
- Compressão Latente (MLA): Reduz drasticamente o consumo de memória do cache KV projetando cabeças de atenção em vetores latentes de baixa dimensão.8
- Atenção Distribuída (Ring/Flex): Distribui o cálculo da atenção através de múltiplos chips (TPUs/GPUs) ou carrega blocos de memória dinamicamente, permitindo que a sequência exceda a memória de um único dispositivo.9
1.3 Computação em Tempo de Inferência (“System 2”)
A maior inovação funcional de 2025 é a integração nativa de “modos de pensamento”. Modelos como GPT-5 e DeepSeek-R1 não apenas prevêem o próximo token; eles geram cadeias de pensamento ocultas (chain-of-thought) que são verificadas e refinadas antes de uma resposta ser apresentada ao usuário. Isso introduz uma nova dimensão de escala: a qualidade da resposta agora é função do tempo de computação gasto durante a inferência, não apenas durante o treinamento.1
2. Análise Profunda dos Modelos de Fronteira
Nesta seção, dissecamos cada um dos oito principais modelos, focando em suas especificidades arquiteturais, inovações matemáticas e diferenças fundamentais em relação ao Transformer padrão.
2.1 OpenAI GPT-5: O Sistema Unificado e a Roteamento Dinâmico
O GPT-5, lançado no final de 2025, representa a consolidação da estratégia da OpenAI de criar um sistema onipotente e multimodal. Diferente de seus antecessores que dependiam de módulos separados costurados, o GPT-5 é um sistema unificado “Omni”, onde texto, áudio e vídeo compartilham o mesmo espaço de embedding e processamento.4
Arquitetura Base: MoE Unificado e Roteamento Preditivo
O GPT-5 não é um único modelo monolítico, mas um sistema orquestrado por um Roteador Preditivo. Este componente, baseado em uma rede neural leve, analisa a complexidade do prompt do usuário e decide dinamicamente qual configuração do modelo ativar:
- GPT-5-Main (Alta Vazão): Uma configuração MoE esparsa otimizada para latência e tarefas rotineiras.
- GPT-5-Thinking (Raciocínio Profundo): Uma configuração que ativa o modo de “Cadeia de Pensamento”, utilizando Reinforcement Learning from Verifiable Rewards (RLVR) para decompor problemas complexos, gerar passos intermediários e auto verificar a lógica antes da resposta final.4
Inovação em Atenção: Cluster-Based Sparse Attention
Para lidar com janelas de contexto de até 400.000 tokens de forma eficiente, o GPT-5 emprega uma variante de Atenção Esparsa Baseada em Clusters. Em vez de cada token atender a todos os outros, os tokens são agrupados semanticamente. A atenção densa é calculada dentro dos clusters, enquanto a atenção entre clusters é esparsa e direcionada apenas a “tokens globais” ou representantes de cluster. Isso reduz a complexidade computacional próxima de O(N) para a maioria das tarefas.14
Diferenças do Transformer Vanilla:
- Multimodalidade Nativa: Fusão precoce (early fusion) de modalidades no nível do token, eliminando codificadores de visão separados.
- Roteamento de Computação: Capacidade de variar o compute por inferência (System 1 vs. System 2) de forma transparente.
- RLVR no Pós-Treinamento: Treinamento focado em verificação de passos lógicos, não apenas na imitação de texto humano.1
2.2 DeepSeek-V3 e R1: A Eficiência Algorítmica Extrema
A DeepSeek, laboratório chinês que chocou o mercado em 2025, introduziu com o DeepSeek-V3 e sua variante de raciocínio R1 as inovações matemáticas mais radicais do ano, focadas em maximizar a eficiência do hardware.3
Arquitetura Base: MoE de Granularidade Fina (DeepSeekMoE)
O DeepSeek-V3 opera com 671 bilhões de parâmetros totais, mas ativa apenas 37 bilhões por token. A diferença crucial para outros MoEs (como o Mixtral) é a granularidade. O modelo utiliza 256 especialistas roteados e 1 especialista compartilhado.
O conceito de Especialista Compartilhado (Shared Expert) é fundamental: ele está sempre ativo e captura conhecimentos gerais e sintaxe, permitindo que os especialistas roteados se foquem em nuances altamente específicas sem precisarem “reaprender” o básico.
A função de roteamento introduz um termo de viés dinâmico (bias term) b_i para balanceamento de carga, eliminando a necessidade de uma “perda auxiliar” (auxiliary loss) no treinamento, que tradicionalmente degradava a performance do modelo principal.3
Inovação Matemática: Multi-Head Latent Attention (MLA)
Para resolver o gargalo de memória do cache KV em longos contextos, o DeepSeek-V3 substituiu a atenção padrão pela Multi-Head Latent Attention (MLA).
No Transformer padrão, a memória do cache KV cresce linearmente e pode exceder a memória da GPU. O MLA comprime os vetores de Chave (K) e Valor (V) em um vetor latente de baixa dimensão c_{KV}.
Matematicamente, em vez de armazenar K e V completos, o modelo armazena o vetor comprimido c_{KV} obtido por uma projeção linear de baixa patente (low-rank):
c_{KV,t} = W_{DKV} h_t
(Leia-se “c índice K-V, t… é igual a… W índice D-K-V… vezes h índice t”)
Durante a inferência, as cabeças de atenção são “reconstruídas” a partir deste vetor latente. Isso reduz o uso de memória do cache KV em aproximadamente 93%, permitindo inferência em batchs massivos ou contextos muito longos em hardware limitado.8
Diferenças do Transformer Vanilla:
- MLA: Substituição completa do Multi-Head Attention padrão por compressão latente.
- Decoupled RoPE: Separação das dimensões rotatórias de posição das dimensões de conteúdo para permitir a compressão sem perda de informação posicional.
- Auxiliary-Loss-Free Balancing: Estratégia de roteamento que não penaliza a função de perda principal.3
2.3 Google Gemini 3: A Escala Infinita via TPUs
O Gemini 3 (evoluído do 2.5) é a resposta do Google baseada em sua infraestrutura proprietária de TPUs (v5e/v6). O foco do Gemini 3 é a escala bruta de contexto, suportando janelas de 1 milhão a 10 milhões de tokens nativamente.17
Arquitetura Base: MoE Esparso Nativo Multimodal
O Gemini 3 foi treinado desde o início como um modelo multimodal. Não existem “adaptadores” visuais; o modelo processa “tokens generalizados” que podem representar patches de vídeo, espectrogramas de áudio ou texto. A arquitetura é um MoE esparso distribuído massivamente.19
Inovação Matemática: Ring Attention e Infini-attention
A capacidade de contexto massiva é viabilizada pela Ring Attention (Atenção em Anel). O cálculo da matriz de atenção QK^T (que tem tamanho N \times N) é impossível de armazenar em um único chip para N=10.000.000.
A Ring Attention distribui a sequência em um anel de dispositivos (TPUs).
- Cada dispositivo calcula a atenção para seu bloco local de queries.
- Os blocos de chaves/valores (K, V) giram pelo anel.
- À medida que os blocos KV passam, o dispositivo atualiza seu cálculo de atenção parcial.
Isso permite que o tamanho do contexto escale linearmente com o número de TPUs disponíveis, sem aproximações.9
Além disso, o mecanismo de Infini-attention combina essa distribuição com uma memória compressiva para contextos ultra-longos, permitindo que o modelo “lembre” de informações passadas que saíram da janela imediata de atenção.21
Diferenças do Transformer Vanilla:
- Ring Attention: Computação distribuída da camada de atenção, não apenas paralelismo de dados.
- Codificação Posicional Apreendida + RoPE: Combinação híbrida para generalização de comprimento extremo.
- Deep Fusion: Processamento intercalado de modalidades em todas as camadas.22
2.4 Meta Llama 4: O Padrão Aberto e a FlexAttention
A família Llama 4 (incluindo variantes Scout, Maverick e Behemoth) redefiniu o ecossistema open weights com suporte a multimodalidade nativa e contextos de 10 milhões de tokens, otimizados para execução em GPUs comerciais (H100/Blackwell).5
Arquitetura Base: Híbrido Denso-MoE (“Sandwich”)
O Llama 4 adota uma arquitetura híbrida onde camadas de atenção densa são intercaladas com blocos MoE. Isso estabiliza o treinamento e melhora a representação de características comuns, enquanto os blocos MoE fornecem a capacidade esparsa necessária para escalar parâmetros (até 400B+ no modelo Maverick) sem explodir o custo de inferência.24
Inovação Matemática: FlexAttention e iRoPE
Para viabilizar contextos de 10M tokens em GPUs (que têm menos memória interconectada que os pods de TPU), a Meta desenvolveu a FlexAttention.
Diferente da atenção esparsa fixa, a FlexAttention utiliza um kernel customizado que carrega dinamicamente blocos do cache KV da memória HBM para a memória rápida (SRAM) da GPU apenas quando necessário, baseado em uma máscara de atenção lógica. Isso permite calcular a atenção exata sem materializar a matriz N \times N completa na memória.10
O iRoPE (Interleaved Rotary Positional Embeddings) é outra inovação crítica. O RoPE padrão falha em contextos extremos devido a oscilações de alta frequência. O iRoPE intercala as frequências posicionais de maneira a criar uma curva de extrapolação mais suave, permitindo que o modelo generalize para sequências muito maiores que as vistas no treinamento.24
Diferenças do Transformer Vanilla:
- iRoPE: Codificação posicional intercalada para extrapolação infinita.
- FlexAttention: Kernel de atenção compilado dinamicamente para gestão de memória.
- SwiGLU: Função de ativação gating (padrão desde Llama 2, mantida por eficiência).27
2.5 Anthropic Claude 4: Atenção Adaptativa e Agência
O Claude 4 (modelos Opus e Sonnet) foca em confiabilidade, raciocínio estendido e uso de ferramentas via Model Context Protocol (MCP). A Anthropic prioriza a segurança (“Constitutional AI”) e a capacidade de manter coerência em tarefas longas e complexas.28
Arquitetura Base: Transformer de Raciocínio Híbrido
O Claude 4 implementa um mecanismo de Raciocínio Híbrido. Ele não opera apenas em modo rápido ou lento, mas ajusta dinamicamente a profundidade do processamento. O modelo pode entrar em um modo de “Extended Thinking” (Pensamento Estendido), onde aloca mais ciclos de computação para verificar fatos internamente ou consultar ferramentas externas antes de gerar a resposta visível.6
Inovação Matemática: Atenção Adaptativa (Adaptive Attention)
Diferente do MLA da DeepSeek ou do Ring do Google, o Claude 4 foca na seletividade. Seu mecanismo de Atenção Adaptativa aprende a ponderar dinamicamente a importância de diferentes segmentos do contexto. Em vez de uma máscara fixa (esparsa), o modelo gera uma máscara de atenção “suave” que pode ignorar grandes seções irrelevantes do contexto de 500k tokens, focando intensamente nos segmentos críticos para a tarefa atual. Isso é suportado por uma memória persistente (Working Notes) que atua como um bloco de notas externo ao vetor de contexto.6
Diferenças do Transformer Vanilla:
- Gating de Estado Oculto: Mecanismos que permitem ao modelo “pular” camadas ou blocos de processamento para tokens simples.
- MCP Integration: Camada de interface padronizada para ferramentas externas embutida no pré-treinamento.
- Constitutional AI: Camadas de alinhamento via RLAIF (Reinforcement Learning from AI Feedback) integradas profundamente.6
2.6 Qwen 3: O Equilibrista do Orçamento de Pensamento
O Qwen 3, da Alibaba, destaca-se pela introdução do conceito de Orçamento de Pensamento (Thinking Budget) controlável pelo usuário e pela otimização extrema para implantação.30
Arquitetura Base: MoE com Thinking Budget
O Qwen 3 integra nativamente os modos de pensamento e não-pensamento. O usuário pode definir um parâmetro thinking_level ou um orçamento de tokens que o modelo pode gastar “raciocinando” (gerando tokens ocultos) antes de responder. Isso dá controle granular sobre o trade-off latência/qualidade.30
Componentes Matemáticos: QK-Norm e SwiGLU
Para estabilizar o treinamento em escalas massivas, o Qwen 3 removeu os viéses (biases) das projeções Q, K e V (QKV-bias removal) e introduziu a QK-Norm. A QK-Norm aplica uma normalização (LayerNorm ou RMSNorm) diretamente às Queries e Keys antes do cálculo do produto escalar da atenção. Isso previne instabilidades numéricas quando a magnitude dos vetores cresce em modelos muito profundos.30
Diferenças do Transformer Vanilla:
- QK-Norm: Normalização pré-atenção para estabilidade.
- Dual-Mode: Integração de checkpoints de raciocínio (CoT) e chat padrão no mesmo modelo.
- Tie Embedding: Compartilhamento de pesos entre as camadas de embedding de entrada e saída (em modelos menores) para economizar parâmetros.30
2.7 Grok 4 (e 3): A Busca pela Verdade e Atenção Esparsa
O Grok 4 (evolução direta do Grok 3 e variantes como 4.1 mencionadas) da xAI foca em acesso a dados em tempo real e uma arquitetura robusta para “busca da verdade” (Truth-seeking), minimizando alucinações via RL agressivo.2
Arquitetura Base: MoE Esparso (Top-2 Routing)
O Grok segue uma arquitetura MoE clássica, similar ao Grok-1, mas escalada massivamente. Ele utiliza um roteamento Top-2, onde cada token é enviado para apenas dois especialistas. Isso mantém a eficiência de inferência alta. A inovação está na escala: o modelo é treinado em um cluster massivo (Colossus) com mais de 100.000 GPUs H100/H200, permitindo um pré-treinamento em datasets significativamente maiores que seus competidores.34
Componentes Matemáticos: Roteamento Balanceado sem Perda Auxiliar
Similar ao DeepSeek, o Grok adota estratégias para evitar o colapso do roteamento (onde apenas alguns especialistas são usados). No entanto, a xAI foca em Verificação Formal durante o treinamento, utilizando solucionadores matemáticos (como Z3) para garantir a consistência lógica das respostas em tarefas de raciocínio, integrando essas verificações como sinais de recompensa no RLHF.36
Diferenças do Transformer Vanilla:
- Atenção Esparsa: Implementação agressiva de atenção esparsa para lidar com contextos longos e múltiplos fluxos de dados (X/Twitter em tempo real).
- Verificação Formal: Integração de solvers lógicos no loop de treinamento.
- GeGLU: Variantes de ativação Gated Gaussian Linear Unit para melhor expressividade nos FFNs.33
2.8 Mistral Large 3: A Eficiência Europeia
O Mistral Large 3 continua a tradição da Mistral AI de máxima eficiência por parâmetro. É um modelo MoE esparso que compete com modelos 10x maiores em benchmarks.7
Arquitetura Base: MoE Granular
O Mistral Large 3 utiliza uma arquitetura MoE com 675 bilhões de parâmetros totais, mas apenas 41 bilhões ativos. A relação de esparsidade (aprox. 16:1) é extremamente alta, permitindo que o modelo rode em hardware relativamente modesto (como um único nó de 8 GPUs H100) enquanto mantém conhecimento de nível GPT-5.37
Componentes Matemáticos: Atenção Deslizante e Kernels Blackwell
A Mistral popularizou a Sliding Window Attention (Atenção em Janela Deslizante), onde cada token atende apenas a uma janela local, com camadas superiores tendo acesso global teórico. No Large 3, isso é combinado com otimizações de kernel específicas para a arquitetura Blackwell da NVIDIA, permitindo o uso de precisão mista FP8/NVFP4 para acelerar a inferência sem perda perceptível de qualidade.37
3. Tabela Comparativa Detalhada: LLMs Frontier (Dezembro 2025)
A tabela abaixo sintetiza as especificações técnicas, arquiteturais e matemáticas dos modelos analisados.
| Característica | GPT-5 (OpenAI) | Claude 4 (Anthropic) | Gemini 3 (Google) | Llama 4 (Meta) | DeepSeek-V3/R1 | Qwen 3 (Alibaba) | Grok 4 (xAI) | Mistral Large 3 |
| Arquitetura Base | Sistema Unificado Omni (MoE Esparso + Roteador) | Transformer Híbrido de Raciocínio (MoE) | MoE Esparso Nativo Multimodal (Deep Fusion) | Híbrido Denso-MoE (“Sandwich”) | MoE de Granularidade Fina (256 Experts) | MoE & Denso (Thinking & Non-Thinking) | MoE Esparso (Top-2 Routing) | MoE Esparso Granular (16:1 Ratio) |
| Mecanismo de Atenção | Cluster-Based Sparse Attention | Adaptive Attention (Máscara Dinâmica) | Ring Attention & Infini-attention | FlexAttention (Blocos Dinâmicos) | Multi-Head Latent Attention (MLA) | Grouped Query Attention (GQA) | Sparse Attention (Topologia Otimizada) | Sliding Window + GQA |
| Componentes Matemáticos | Roteamento Preditivo; RLVR | Gating de Estado Oculto; MCP | Softmax Distribuído (Ring); Generalized Tokens | iRoPE (Interleaved RoPE); SwiGLU | Compressão Latente Low-Rank (c_{KV}); Decoupled RoPE | QK-Norm; SwiGLU; Tie Embedding | Verificação Formal (Z3/Lean); GeGLU | Blackwell Attention Kernels; FP8 Quant |
| Roteamento MoE | Dinâmico por tarefa (System 1/2) | Ativação baseada em complexidade | Top-K Gating distribuído em TPUs | Top-2 Gating com camadas densas | Auxiliary-Loss-Free Balancing (Bias only) | Top-K com Shared Experts | Top-2 Routing (Eficiência de Inferência) | Roteamento Esparso Otimizado (41B ativos) |
| Diferenças do Vanilla | Fusão multimodal precoce; Raciocínio Oculto | Memória Persistente; Uso de Ferramentas Nativo | Contexto Infinito Distribuído; Multimodalidade | Extrapolação de Contexto (iRoPE); Open Weights | Compressão KV Massiva (MLA); Roteamento Fino | Normalização Pré-Atenção (QK-Norm) | Integração Real-Time Data; Formal Verification | Janela Deslizante; Quantização Nativa |
| Janela de Contexto | ~200k – 400k | 200k – 500k | 1M – 10M+ | 10M (Scout) | 128k (Extensível) | 128k – 1M | ~1M | 256k |
| Parâmetros (Estimados) | Não revelado (Sistema) | Opus: ~500B+ / Sonnet: ~100B | 1T+ Total / ~20B Ativos (Pro) | 400B Total / 17B Ativos (Maverick) | 671B Total / 37B Ativos | 235B Total / 22B Ativos | ~1.5T Total (Grok 3 base) | 675B Total / 41B Ativos |
| Fontes Principais | 4 | 6 | 9 | 5 | 3 | 30 | 33 | 7 |
4. Aprofundamento nos Componentes Matemáticos Transversais
A análise da tabela acima revela que o diferencial competitivo em 2025 reside na matemática da eficiência. Exploraremos agora os três pilares matemáticos que sustentam essas inovações.
4.1 A Matemática da Compressão de Atenção (MLA vs. FlexAttention)
O DeepSeek-V3 demonstrou que a compressão do cache KV via MLA é superior à simples quantização.
A projeção padrão de atenção é:
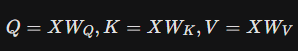
Q = XW_Q, K = XW_K, V = XW_V
(Leia-se “A matriz Query (Q) é o produto da entrada X pela matriz de pesos W índice Q.” “A matriz Key (K) é o produto da entrada X pela matriz de pesos W índice K.” “A matriz Value (V) é o produto da entrada X pela matriz de pesos W índice V”)
No MLA, K e V são gerados a partir de um vetor latente comprimido c _{KV}:
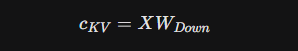
c_{KV} = X W_{Down}
(Leia-se “c índice K-V… é igual a… X vezes W índice Down.”)
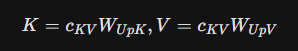
K = c_{KV} W_{UpK}, V = c_{KV} W_{UpV}
(Leia-se “K é igual a… c índice K-V… vezes W índice Up-K.”. “V é igual a… c índice K-V… vezes W índice Up-V.”)
A economia vem do fato de que a dimensão de c_{KV} é muito menor que a dimensão combinada de todas as cabeças de K e V. Isso reduz o tráfego de memória (Memory Bandwidth Usage) durante a decodificação, que é o principal gargalo em GPUs.
Em contraste, o Llama 4 com FlexAttention não comprime os dados, mas otimiza o acesso. Ele usa uma máscara lógica M para determinar quais blocos da matriz de atenção A_{ij} precisam ser calculados.
Attention(Q, K, V) = \text{softmax}(M \odot (QK^T))V
(Leia-se “Attention de Q, K e V… é igual a… Softmax de… M multiplicado elemento-a-elemento pelo produto de Q por K transposto… tudo isso vezes V.”)
O kernel da FlexAttention carrega para a SRAM apenas os blocos onde M_{ij} = 1, permitindo que o modelo ignore vastas áreas de contexto irrelevante sem perder a precisão nos blocos relevantes. Isso é crucial para a arquitetura de 10 milhões de tokens.10
4.2 Roteamento MoE: O Dilema do Balanceamento
O problema clássico do MoE é o “colapso do especialista”, onde o roteador aprende a enviar todos os tokens para os mesmos 2 ou 3 especialistas, tornando os outros inúteis.
A abordagem tradicional adiciona uma Auxiliary Loss (L_{aux}) à função de custo:
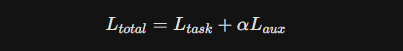
L_{total} = L_{task} + \alpha L_{aux}
Onde L_{aux} penaliza o desequilíbrio. O problema é que isso compete com a performance da tarefa (L_{task}).
O DeepSeek-V3 resolveu isso removendo L_{aux} e usando apenas um viés (bias) no logit do roteador:
Gate(x)_i = \text{Softmax}(x \cdot e_i + b_i)
(Leia-se “Gate de x, no índice i… é igual a… Softmax de… x vezes e índice i… mais b índice i.”)
Onde b_i é ajustado dinamicamente durante o treinamento para forçar o equilíbrio, mas não afeta o gradiente da tarefa principal. Isso resultou em especialistas mais especializados e melhor performance final.3
4.3 Raciocínio Verificável (RLVR)
O DeepSeek-R1 e o GPT-5 Thinking utilizam uma abordagem de treinamento onde o modelo gera uma trajetória de pensamento \tau = (s_1, s_2,…, s_T). A recompensa R não vem de um humano, mas de um verificador determinístico (ex: compilador de código).
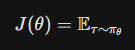
J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta}
(Leia-se “J de teta… é igual à… Esperança… onde tau é amostrado de pi índice teta.”)
O uso de algoritmos como GRPO (Group Relative Policy Optimization) permite que o modelo explore múltiplas cadeias de raciocínio e aprenda a “voltar atrás” (backtracking) quando detecta um erro lógico, sem a necessidade de um modelo “crítico” de valor (value model) tão pesado quanto no PPO tradicional. Isso democratizou o treinamento de modelos de raciocínio.1
5. Conclusão e Perspectivas para 2026
A análise exaustiva dos LLMs frontier de dezembro de 2025 indica que a indústria moveu-se além da força bruta. A vitória não pertence mais a quem tem o maior cluster de GPUs, mas a quem possui a melhor arquitetura de eficiência.
- Atenção é o Novo Campo de Batalha: Com MLA, Ring e FlexAttention, a barreira da memória foi quebrada. Espera-se que em 2026 modelos com contexto “infinito” (streaming contínuo) se tornem o padrão para assistentes pessoais e análise de dados corporativos.
- Especialização via MoE: O modelo denso está morto para a fronteira. O futuro é de arquiteturas MoE cada vez mais granulares (como os 256 experts do DeepSeek) ou hierárquicas.
- Raciocínio como Commodity: A capacidade de “pensar” (System 2) agora é uma feature ativável sob demanda (como no Qwen 3 e GPT-5), permitindo que os usuários escolham pagar com latência por maior inteligência.
- Hardware e Software Co-Design: A vantagem do Google com o Gemini 3 e TPUs, e da Meta com o Llama 4 e H100s, mostra que o design do modelo está inextricavelmente ligado à arquitetura do chip.
Para pesquisadores e engenheiros, 2025 deixa a lição de que a inovação matemática — como a compressão latente e o roteamento sem perda auxiliar — é tão potente quanto a escala de dados. O próximo passo lógico é a fusão dessas inovações: um modelo que combine o MLA da DeepSeek, a Ring Attention do Google e a infraestrutura de agência do Claude.
Referências citadas
- 2025 LLM Year in Review – 3 Quarks Daily, acessado em dezembro 31, 2025, https://3quarksdaily.com/3quarksdaily/2025/12/2025-llm-year-in-review.html
- Top LLMs 2025: Best Models for Modern AI Systems Explained, acessado em dezembro 31, 2025, https://www.thesys.dev/blogs/top-llms
- DeepSeek-V3 Technical Report, acessado em dezembro 31, 2025, https://arxiv.org/pdf/2412.19437
- GPT-5: A Technical Analysis of Its Evolution & Features – Cirra AI, acessado em dezembro 31, 2025, https://cirra.ai/articles/gpt-5-technical-overview
- Llama 4 Explained: Architecture, Long Context, and Native …, acessado em dezembro 31, 2025, https://www.youtube.com/watch?v=Lqj69tZkPiE
- Anthropic Claude 4: Evolution of a Large Language Model, acessado em dezembro 31, 2025, https://intuitionlabs.ai/articles/anthropic-claude-4-llm-evolution
- Mistral AI Models 2025: European AI Excellence Guide for …, acessado em dezembro 31, 2025, https://local-ai-zone.github.io/brands/mistral-ai-european-excellence-guide-2025.html
- DeepSeek-V3 Explained 1: Multi-head Latent Attention – Medium, acessado em dezembro 31, 2025, https://medium.com/data-science/deepseek-v3-explained-1-multi-head-latent-attention-ed6bee2a67c4
- RingAttention with Blockwise Transformers for Near-Infinite Context, acessado em dezembro 31, 2025, https://openreview.net/forum?id=WsRHpHH4s0
- Paged Attention Meets FlexAttention: Unlocking Long-Context …, acessado em dezembro 31, 2025, https://arxiv.org/html/2506.07311v1
- DeepSeek R1 vs. V3: Choosing the Right Model for Your AI Needs, acessado em dezembro 31, 2025, https://www.hiberus.com/en/blog/deepseek-r1-vs-v3-choosing-the-right-model-for-your-ai-needs/
- Top 9 Large Language Models as of December 2025 | Shakudo, acessado em dezembro 31, 2025, https://www.shakudo.io/blog/top-9-large-language-models
- GPT-5: Another (Sparse) Giant AI From The Biggest Name In The West, acessado em dezembro 31, 2025, https://www.verdantix.com/client-portal/blog/gpt-5–another-sparse-giant-ai-from-the-biggest-name-in-the-west
- Efficient Attention Mechanisms for Large Language Models: A Survey, acessado em dezembro 31, 2025, https://arxiv.org/html/2507.19595v1
- DeepSeek-V3.2 Release, acessado em dezembro 31, 2025, https://api-docs.deepseek.com/news/news251201
- DeepSeek-V3 (and R1!) Architecture | by Gal Hyams | Medium, acessado em dezembro 31, 2025, https://medium.com/@galhyams/deepseek-v3-and-r1-architecture-5e5ae796c7a9
- Introducing Gemini 2.0: our new AI model for the agentic era, acessado em dezembro 31, 2025, https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/
- A new era of intelligence with Gemini 3 – Google Blog, acessado em dezembro 31, 2025, https://blog.google/products/gemini/gemini-3/
- Gemini 2.5: Pushing the Frontier with Advanced Reasoning …, acessado em dezembro 31, 2025, https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
- Building Vision AI with Gemini 3: The Complete Guide – GetStream.io, acessado em dezembro 31, 2025, https://getstream.io/blog/gemini-vision-ai-capabilities/
- Google DeepMind’s Technique Powering Gemini 2M Token Window, acessado em dezembro 31, 2025, https://pub.towardsai.net/inside-infini-attention-google-deepminds-technique-powering-gemini-2m-token-window-4564bd43e720
- Google’s Gemini 3 Pro: The Architectural Leap That Redefined …, acessado em dezembro 31, 2025, https://medium.com/@shashwatabhattacharjee9/googles-gemini-3-pro-the-architectural-leap-that-redefined-multimodal-ai-8058cf35751a
- Evolution of Meta’s LLaMA Models and Parameter-Efficient Fine …, acessado em dezembro 31, 2025, https://arxiv.org/html/2510.12178v1
- Llama 4 Revolution: A New Era of Multimodal AI – Primotech, acessado em dezembro 31, 2025, https://primotech.com/llama-4-revolution/
- Llama4 – Hugging Face, acessado em dezembro 31, 2025, https://huggingface.co/docs/transformers/model_doc/llama4
- What’s New in Llama 4 – A Practical Overview – RisingStack blog, acessado em dezembro 31, 2025, https://blog.risingstack.com/llama-4-overview/
- The Llama Model Family: Architecture Evolution from Llama (1) to …, acessado em dezembro 31, 2025, https://medium.com/@akdemir_bahadir/the-llama-model-family-architecture-evolution-from-llama-1-to-llama-4-76eb405e5f91
- Models overview – Claude Docs, acessado em dezembro 31, 2025, https://platform.claude.com/docs/en/about-claude/models/overview
- Introducing Claude 4 in Amazon Bedrock, the most powerful models …, acessado em dezembro 31, 2025, https://aws.amazon.com/blogs/aws/claude-opus-4-anthropics-most-powerful-model-for-coding-is-now-in-amazon-bedrock/
- Qwen3 Technical Report, acessado em dezembro 31, 2025, https://arxiv.org/pdf/2505.09388
- Gemini 3 Developer Guide | Gemini API – Google AI for Developers, acessado em dezembro 31, 2025, https://ai.google.dev/gemini-api/docs/gemini-3
- qwen3_from_scratch.ipynb – GitHub Gist, acessado em dezembro 31, 2025, https://gist.github.com/vukrosic/94dc965a22b0892042f44fed25918598
- The Tech Behind Elon Musk’s xAI latest release – Grok 3, acessado em dezembro 31, 2025, https://mohasoftware.com/blog/the-tech-behind-elon-musks-xai-latest-release-grok-3
- Grok 3 Technical Review: Unveiling the Next-Generation AI Model, acessado em dezembro 31, 2025, https://futureagi.com/blogs/grok-3-technical-review-2025
- Grok 3 Beta — The Age of Reasoning Agents – xAI, acessado em dezembro 31, 2025, https://x.ai/news/grok-3
- Grok-3: Architecture Beyond GPT-4 – Zenodo, acessado em dezembro 31, 2025, https://zenodo.org/records/15227014/files/Grok3_Architecture_Beyond_GPT4_Afridi.pdf
- Mistral Large 3: An Open-Source MoE LLM Explained | IntuitionLabs, acessado em dezembro 31, 2025, https://intuitionlabs.ai/articles/mistral-large-3-moe-llm-explained
- Attention Is All You Need – Wikipedia, acessado em dezembro 31, 2025, https://en.wikipedia.org/wiki/Attention_Is_All_You_Need
- FlexAttention: Scalable, Flexible Attention – Emergent Mind, acessado em dezembro 31, 2025, https://www.emergentmind.com/topics/flexattention
- Best AI Models: Your Complete LLM Guide for 2025 – Inkeep, acessado em dezembro 31, 2025, https://inkeep.com/blog/best-ai-models-2025
- Everything you should know about GPT-5 [September 2025] – Botpress, acessado em dezembro 31, 2025, https://botpress.com/en/blog/everything-you-should-know-about-gpt-5
- How has DeepSeek improved the Transformer architecture?, acessado em dezembro 31, 2025, https://epoch.ai/gradient-updates/how-has-deepseek-improved-the-transformer-architecture
- Mistral Large 3, acessado em dezembro 31, 2025, https://docs.mistral.ai/models/mistral-large-3-25-12
- Claude 4 vs LLaMA 4: Benchmarking Technical Capabilities – Medium, acessado em dezembro 31, 2025, https://medium.com/@bob.mashouf/claude-4-vs-llama-4-benchmarking-technical-capabilities-55b99c17d3f7
- Best LLM Leaderboards: A Comprehensive List – Nebuly, acessado em dezembro 31, 2025, https://www.nebuly.com/blog/llm-leaderboards
- Blog Llama 4: What You Need to Know – IREN, acessado em dezembro 31, 2025, https://iren.com/resources/blog/llama-4-what-you-need-to-know
- [D] How does Gemini 1.5 Pro recall information in 10M context?, acessado em dezembro 31, 2025, https://www.reddit.com/r/MachineLearning/comments/1bc1ydg/d_how_does_gemini_15_pro_recall_information_in/
Share this content: